How to Find & Fix Duplicate Content on Your Website
 Timothy Carter
Timothy Carter
Duplicate content can be bad. Using the same content, either in total or partial form, on your website leads to a poor user experience, and triggers a red flag in Google’s search algorithm. In the old days of SEO, duplicate content was often used as a cheap trick to get more keywords and more content on a website, so Google evolved a system to weed out the spammers who violated best practices by doing this. Today, if you’re caught using duplicate content, your domain authority could suffer and your keyword rankings could drop. In this post we discuss:
- What is duplicate content? Why is it bad?
- Content syndication & duplicate content
- What other content production tools can cause duplicate content?
- Types of duplicate content. Which are benign, which are toxic.
- How does Generative AI (artificial intelligence) content fit into the mix?
- How to avoid and/or clean up duplicate content
Duplicate Content Defined
In the vast majority of cases, duplicate content is non-malicious and simply a product of whichever CMS (content management system) the website happens to be running on. For example, WordPress (the industry-standard CMS) automatically creates “Category” pages and “tag” duplicate pages which list all blog posts within certain categories or tags. Or, the www vs.ur non-www version of a site may not be redirected properly, causing duplicate content from multiple URLs. This creates multiple pages or URL parameters within the domain that contain the same content. 1) Google may decide to let me off with a “warning” and simply choose not to index 99 of my 100 duplicate posts, but keep one of them indexed. NOTE: This doesn’t mean my website’s search rankings would be affected in any way by the duplicate content. 2) Google may decide it’s such a blatant attempt at gaming the system that it completely de-indexes my entire website from all search results. This means that, even if you searched directly for “Example.com” Google would find no results. So, one of those two scenarios is guaranteed to happen. Which one it is depends on how egregious Google determines your blunder to be. In Google’s own words:
Duplicate content on a site is not grounds for action on that site unless it appears that the intent of the pages with duplicate content is to be deceptive and manipulate search engine results. If your site suffers from duplicate content issues, and you don’t follow the advice listed above, we do a good job of choosing a canonical version of the content to show in a given search result. This type of non-malicious duplication is fairly common, especially since many
CMS
s don’t handle this well by default. So when people say that having this type of duplicate content can affect your site, it’s not because you’re likely to be penalized; it’s simply due to the way that web sites and search engines work.
Most search engines strive for a certain level of variety; they want to show you ten different results on a search results page, not ten different URLs that all have the same content. To this end, Google tries to filter out duplicate content and documents so that users experience less redundancy. So, what happens when a search engine crawler detects duplicate content? (from https://searchengineland.com/search-illustrated-how-a-search-engine-determines-duplicate-content-13980)
How to Find Duplicate Content
Fixing duplicate content is relatively easy. Finding duplicate content is the hard part. Like I mentioned above, duplicate content can be tricky to detect—just because you don’t have any repeated content from a user experience perspective doesn’t mean you don’t have repeated content from a search algorithm’s perspective. Your first step is a manual one; go through your site and see if there are any obvious repetitions of content. As an example, do you have an identical paragraph concluding each of the pages on your site? Rewrite it. Did you re-use a section of a past blog post in a new post? Make a distinction. Once you’ve completed this initial manual scan, there are two main tools you can use to find more, better hidden instances of duplicate content.
Perform Your Own Search
First, you can perform a search to see through Google’s eyes. Use a Site: tag to restrict your search to your site only, and follow up with an intitle: tag to search for a specific phrase. It should look a little something like this: Site:thisisyoursite.comintitle:”thisisyourtargetphrase” This search will generate all the results on your given site that correlate to your chosen phrase. If you see multiple identical results, you know you have a duplicate content problem.
Check Google Search Console (GSC)
A simpler way to check for duplicate content is to use Google Webmaster Tools to crawl your site and report back on any errors. Once you’ve created and verified your Webmaster Tools account, head to the Search Appearance tab and click on “HTML Improvements.” Here, you’ll be able to see and download a list of duplicate meta descriptions and title tags. These are common and easily fixable issues that just require a bit of time to rewrite. To determine whether a sample of duplicate content is going to pull down your rankings, first you have to determine why you are going to publish such content in the first place. It all boils down to your purpose. If your goal is to try to punk the system by using a piece of content that has been published elsewhere, you’re bound to get penalized. The purpose is clearly deceptive and intended to manipulate search results. This is what Google has to say about this sort of behavior:
Duplicate content on a site is not grounds for action on that site unless it appears that the intent of the duplicate content is to be deceptive and manipulate search engine results.
Copyscape
For 5 cents per search, you can have Copyscape vet an entire piece for you. But if your budget won’t allow that kind of expenditure, you can still use Copyscape for free. The catch with free Copyscape is that you’ll have to publish the content online first to retrieve its URL. Copy and paste the URL of your newly published content in Copyscape’s search box. What Copyscape does is scan the entire interwebs for any copies of the content you’ve just published. Copyscape is a reliable tool that many publishers depend on heavily to check for quality and originality. There are other tools very similar to Copyscape that you can use for the same purpose, such as Plagiarism Detect and InterNIC. Checking for duplicate content is fairly easy and simple. It’s an indispensable SEO task for beginners, but no one should take it for granted. With the right set of tools, you can comfortably ensure that your content is unique well before you publish it online. And by providing your readers with high-quality and unique content, you will have furnished great value.
How to Clean & Remove Duplicate Content
Once you’ve identified the critical areas of duplication on your site, you can start taking action to correct them. The sooner you take corrective action, the sooner you’ll start rebounding from the negative effects. Fortunately, Google also makes it easy for you to find and correct duplicate content on your site. When you log into Google Webmaster Tools, head to “Search Appearance,” and then “HTML Improvements.” This will allow you to generate a list of any pages that Google detects duplicate content. Once you have this list, you can begin eliminating the duplicate content errors one by one with any of the following methods:
- Eliminate Unnecessary and Duplicate Content. The first step is the easiest and the most obvious, though it can be time-consuming if you have several instances. In any situation where you can rewrite a piece of content in order to resolve the duplication, do it. Put your ideas into different words, use different framing devices, and don’t be afraid to rewrite from the ground up.
- Boilerplates. Long boilerplates or copyright notices should be removed from various pages and placed on a single page instead. In cases where you would have to call your readers’ attention to boilerplate or copyright at the bottom of each of your pages or posts, insert a link to the single special page instead.
- Similar pages. There are cases when similar or potentially duplicate pages must be published, such as SEO for small and big businesses. Avoid publishing the same or similar information. Instead, expand on both services and make the information very specific to each business segment.
- Noindex. People could be syndicating your content. If there’s no way to avoid this, include a note at the bottom of each page of your content that asks users to include a “noindex” metatag on your syndicated content to prevent the duplicate content from being indexed by the search engines.
- 301 redirects. Let the Googlebot web crawlers know that a page has permanently moved by using 301 redirects. This also alerts the search engines to remove the old URL from their index and replace it with the new address.
- Choosing only one URL in Session IDs. There might be several URLs you could use to point to your homepage, but you should choose only one. When choosing the best URL for your page, be sure to keep the users in mind. Make the URL user-friendly and be careful with session IDs. This makes it easier not only for your users to find your page, but also for the search engines to index your site. Some duplicate content errors aren’t due to actual duplicate content. Session IDs have to do with the URL structure that Google sees. For example, if you have one page that is associated with thisisyoursite.com/, thisisyoursite.com/?, and thisisyoursite.com/?sessionid=111, Google will see that page as repeating content three times. First, choose between www or non-www formatting and stick to that.
- Always create unique content. Affiliates almost always fall victim to the convenience of ready-made content provided by merchants. If you are an affiliate, be sure to create unique content for the merchant products you are promoting. Don’t just copy and paste.
How Google Penalizes Duplicate Content
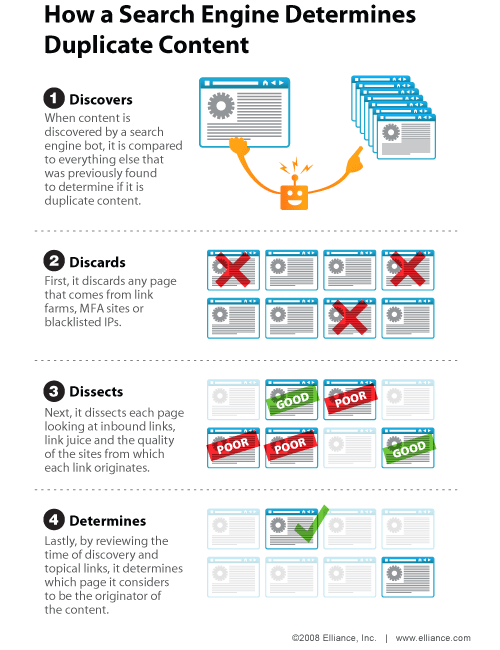
Google is fairly open about its duplicate content policies, including the potential of giving sites a duplicate content penalty if they fail to comply. According to their reports, if Google encounters two different versions of the same web page, or content that is appreciably similar to onsite content elsewhere, it will randomly select a canonical page version to index. You can signal to Google directly which page you want to be the main page with the simple use of the rel=“canonical” tag in your hyperlink. The example they give is this: imagine you have a standard web page and a printer-friendly version of that same web page, complete with identical content. Google would pick one of these pages at random to index, and completely ignore the other version. When using link rel="canonical" href it doesn’t imply anything about suffering a penalty, but it’s in your best interest to make sure Google is properly indexing and organizing your site. The real trouble with a rel="canonical" link comes in when Google suspects duplicate content created maliciously or manipulatively. Basically, if Google thinks your duplicate content was an effort to fool their ranking algorithm even if a rel="canonical" URL is included, you’ll face punitive action. It’s in your best interest to clear up any errors and add rel="canonical" link to your HTML text well in advance to prevent such a fate for your site.
Syndication: Duplicate Content Across Domains
Sometimes, the same piece of content can appear word-for-word across different URLs. Some examples of this include:
- News articles (think Associated Press)
- The same article from an article directory being picked up by different Webmasters
- Webmasters submitting the same content to different article directories
- Press releases being distributed across the Web
- Product information from a manufacturer appearing across different e-commerce Websites
All these examples result from content syndication. The Web is full of syndicated content. One press release can create duplicate content across thousands of unique domains. But search engines strive to deliver a good user experience to searchers, and delivering a results page consisting of the same pieces of content would not make very many people happy. So what is a webcrawler supposed to do? Somehow, it has to decide which location of the content is the most relevant to show the searcher. So how does it do that? Straight from the big G:
When encountering such duplicate content on different sites, we look at various signals to determine which site is the original one, which usually works very well. This also means that you shouldn’t be very concerned about seeing negative effects on your site’s presence on Google if you notice someone scraping your content.
Well, Google, I beg to differ. Unfortunately, I don’t think you’re very good at deciding which site is the originator of the content. Neither does Michael Gray, who laments in his blog post "When Google Gets Duplicate Content Wrong” that Google often attributes back to the original content to other sites to which he syndicates his content. According to Michael:
However the problem is with Google, their ranking algo IMHO places too much of a bias on domain trust and authority.
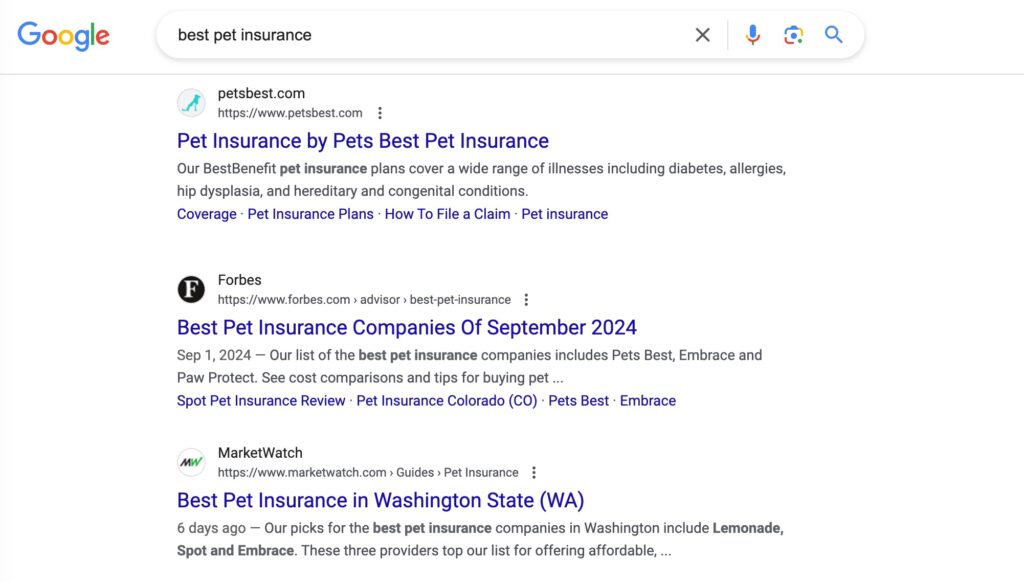
And I agree with Michael. It's one of the reasons Forbes Marketplace has dominated the SERPs for unrelated topics like "pet insurance":
For much of my internet marketing career, I have syndicated full articles to various article directories in order to expand the reach of my content while also using it as “SEO fuel” to get white hat backlinks to my websites. According to Google, as long as your syndicated versions contain a backlink to your original, this will help your case when Google decides which piece is the original. Here’s proof: First, a video featuring John Mueller, a well-known blogger and former engineer for Google: The discussion on syndication starts at about 2:25. At 2:54 he says you can tell people that you’re the “master of the content” by including a link from the syndicated piece back to your original piece. More evidence:
In cases when you are syndicating your content but also want to make sure your site is identified as the original source, it’s useful to ask your syndication partners to include a link back to your original content.
Syndicate carefully: If you syndicate your content on other sites, Google will always show the version we think is most appropriate for users in each given search, which may or may not be the version you’d prefer. However, it is helpful to ensure that each site on which your content is syndicated includes a link back to your original article. You can also ask those who use your syndicated material to use the noindex meta tag to prevent search engines from indexing their version of the content.
Now, what I think is interesting from this last quote from Google is that they actually admit that the piece of content they choose may not be the right one. In my experience, it’s very likely not to pick the right one if the site that originated the content is relatively young or has a low PageRank.
Duplicate Content On the Same Domain
The final word is that, unless you are reallyblatantly duplicating your content across tons of URLs within the same domain, there’s nothing to worry about. One of your URLs on which the duplicate content resides will be indexed and chosen as the “representative” of that URL cluster. When users perform search queries in the search engines, that particular piece of content will display as a result for relevant queries, and the other URLs in the dupe cluster will not. Simple as that. However, the other side of the coin is duplicate content across different domains. And that’s a whole different monster. Ready to tackle it? Here we go.
Traditional “Duplicate Content”

Traditional duplicate content is the type of content that comes to mind intuitively when you hear the phrase. It is content identical to, or highly similar to, content that exists elsewhere on the web (usually on your own site). There are a handful of reasons a site would intentionally duplicate content:
- Reproducing old content to make your site appear more updated.
- Copying material over and over again to add more pages to your site.
- Plagiarizing material to pass off as your own.
All of these situations are deceitful, sometimes to users and sometimes to Google, and for the most part, webmasters know to stay far away from these practices. If you engage in them, you probably deserve a penalty.
Duplicate page versions
There are four different versions of your website, all of which are treated (or can be treated) as separate websites by search engines:

On the back end, you should have one version designated as your primary site and direct all other versions to that primary site. If Google has indexed multiple versions of your site, it’s going to affect your rankings. For example, if you run a content marketing campaign with links to https://yourdomain.com, only that version of your site will get the “link juice.” If your primary site is actually https://www.yoursite.com, you’ll have to run a separate campaign to rank pages under that domain. Do a site search in Google for all 4 domain formats listed above. If you get results for more than one domain format, talk to a website developer about designating a primary version and redirecting all others to that primary version of your domain.
Sneaky Duplicate Content
I call it “sneaky” duplicate content because of how easily it can sneak up on you. You have no intention of creating duplicate pages, but they can happen anyway. Usually, this is due to a technical hiccup or an unwitting reproduction; for example:
- If you have two versions of your website for https:// and https://, Google may index both versions of each page separately, then mark those pages as instances of duplicate content.
- If you have a “printer friendly” version of a web page, it will display as a separate URL with the same content.
- Full and mobile-modified forms of web pages, like forum sections.
Unfortunately, most of these instances can arise naturally as you build and modify your website, unless you’ve specifically taken preventative action to stop it.
“But I Don’t Copy My Content”
Your first reaction to this evaluation may be one of dismissal. You don’t copy your content from one page to another. You take meticulous care to make sure every page of your site is originally written, with no duplicate phrases or sections. Unfortunately, there’s still a risk for you. What Google registers as “duplicate content” isn’t always what a user sees as duplicate content. A user browsing through your pages may never encounter a repeated phrase, but Google may crawl your site and find dozens of repetitions in your title tags, or you may have multiple non-canonized URLs hosting the same on-page content. Even if you feel confident that you haven’t directly influenced some form of duplicate content, it’s worth checking your site just to be sure.
A Note on Content Produced by Generative AI
While AI content is not technically duplicated, the machines are getting better at understanding what has also been created by a machine. Consequently, any creator of online content that intends on using the likes of ChatGPT, Gemini, Perplexity.ai or any other LLM (large language model) to produce content at massive scale, should be aware of the potential damage they could be doing to the long term viability their own website and brand. Shortcut solutions may work for a time, but the risk associated with using them is likely to outweigh the potential gain to be had from their use, especially for those running ACTUAL online businesses which they want to see exist well into the future.
Conclusion
“Duplicate content” results are easy to track down with Google Search Console and fix with canonicalization adjustments (via rel="canonical" ) or redirects, but if they go unnoticed, they can cumulatively bring your rankings down. Be proactive and scout for duplicate content via an SEO audit at least once every few months—unless your site management process is flawless, it’s probably that duplicate content will surface when you least expect it. In the end, it all comes down to testing on a massive scale, getting solid data and making decisions based on that data. So here’s what I’m going to do. I’m going to run a huge test and then update this post with my results. At the beginning of the post I mentioned that I am soon launching a massive website with tons of unique content. I’m going to syndicate it all, completely unedited, as far and wide as I possibly can. As I do so, I’ll monitor organic traffic sources to see what keywords people are using to find my content. Then, I’ll replicate those keyword queries in Google and see where my site ranks in the search results. This should be the definitive test for the merits of syndication.